

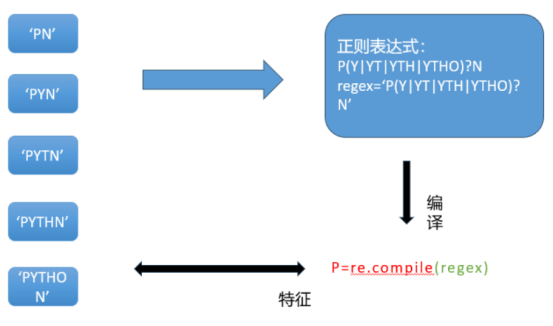
正则表达式(Regular Expression,简称 Regex 或 Regexp)是一种用于文本搜索、匹配、替换等操作的强大工具。它通过定义一组字符和操作符来指定一个搜索模式,这些模式可以用来查找、编辑或操作文本和数据。正则表达式最初由数学家斯蒂芬·克莱尼(Stephen Kleene)在20世纪50年代提出,并在计算机科学中得到了广泛应用。
| 基本元素
1.普通字符:例如字母、数字、标点符号等,这些字符在正则表达式中直接表示它们自身。
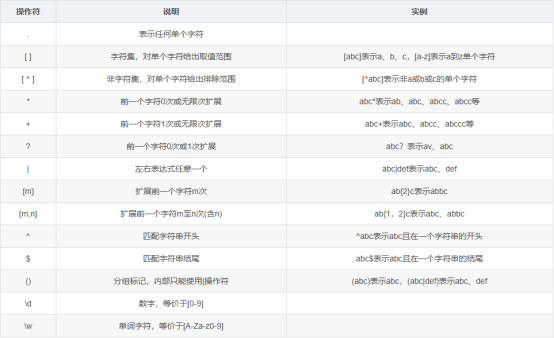
2.元字符:具有特殊含义的字符,如 .、*、+、?、^、$、(、)、[、]、{、}、| 和 \ 等。例如:
. 匹配除换行符以外的任意单个字符。
* 匹配前面的字符零次或多次。
+ 匹配前面的字符一次或多次。
? 匹配前面的字符零次或一次。
^ 匹配字符串的开始位置。
$ 匹配字符串的结束位置。
3.字符类:用方括号 [] 包围的字符集合,匹配方括号中的任意一个字符。例如,[abc] 匹配 a、b 或 c。
4.转义字符:使用反斜杠 \ 来表示一些特殊字符的字面意义,或引入一些特殊的字符序列。例如,\. 匹配 . 字符,\\ 匹配 \ 字符。
5.分组与捕获:使用圆括号 () 来分组表达式,以便将表达式的一部分作为一个整体来处理,还可以捕获匹配的内容以便后续引用。例如,(abc) 可以匹配 abc,并且可以通过 \1 来引用这个匹配。
6.量词:用来指定前面的字符、字符类或分组重复的次数。例如:
{n} 匹配前面的字符恰好 n 次。
{n,} 匹配前面的字符至少 n 次。
{n,m} 匹配前面的字符至少 n 次,但不超过 m 次。
| 用途
正则表达式在多种编程语言(如 Python、JavaScript、Java、C# 等)和工具(如 grep、sed、awk 等)中都有广泛应用,主要用于:
验证输入:检查字符串是否符合特定的格式(如电子邮件地址、电话号码等)。
搜索和替换:在文本中查找特定的模式,并进行替换操作。
提取信息:从文本中提取符合特定模式的子字符串。
| 示例
① 匹配一个电子邮件地址的简单正则表达式:[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}
② 匹配一个包含数字的字符串:\d+(其中 \d 表示任意数字)
③ 匹配以 "Hello" 开头并以 "World" 结尾的字符串:^Hello.*World$
正则表达式的语法和功能非常丰富,掌握它可以大大提高文本处理和数据提取的效率。
了解更多物联网知识和产品:进入塔石物联网
塔石专注于物联网信息产品的开发、生产、销售和技术服务。自2017年成立以来,已推出DTU、串口服务器、RTU、工业路由器/网关、传感器、模块模组6大系列两百多款产品,经过多年的技术沉淀及理论创新,除了成熟的工业设备,我们还为客户提供专业的方案定制和技术支持。







